第三章:纯函数的纯粹快乐
哦,再次纯粹
我们需要弄清楚的一件事是纯函数的概念。
纯函数(pure function)是指满足以下条件的函数:对于相同的输入,总是产生相同的输出,并且没有任何可观察到的副作用(side effect)。
以 slice 和 splice 为例。这两个函数做的事情完全相同——当然,方式大相径庭,但结果是一样的。我们说 slice 是纯的,因为它保证每次对相同的输入都返回相同的输出。然而,splice 会“吃掉”它的数组,并将其永远改变后“吐”出来,这是一种可观察到的副作用。
const xs = [1,2,3,4,5];
// 纯函数
xs.slice(0,3); // [1,2,3]
xs.slice(0,3); // [1,2,3]
xs.slice(0,3); // [1,2,3]
// 非纯函数
xs.splice(0,3); // [1,2,3]
xs.splice(0,3); // [4,5]
xs.splice(0,3); // []
在函数式编程(Functional Programming)中,我们不喜欢像 splice 这样改变(mutate)数据的笨拙函数。这是绝对不行的,因为我们追求的是每次都返回相同结果的可靠函数,而不是像 splice 那样留下烂摊子的函数。
让我们看另一个例子。
// 非纯函数
let minimum = 21;
const checkAge = age => age >= minimum;
// 纯函数
const checkAge = (age) => {
const minimum = 21;
return age >= minimum;
};
在非纯函数部分,checkAge 依赖于可变变量 minimum 来确定结果。换句话说,它依赖于系统状态,这令人失望,因为它引入了外部环境,增加了认知负荷。
在这个例子中,这看起来可能不算什么,但这种对状态的依赖是系统复杂性的最大贡献者之一 (http://curtclifton.net/papers/MoseleyMarks06a.pdf)。 这个 checkAge 函数可能会根据输入之外的因素返回不同的结果,这不仅使其失去了纯函数的资格,而且每次我们推理软件时都会让我们的思维陷入困境。
另一方面,它的纯函数形式是完全自给自足的。我们也可以让 minimum 成为不可变的(immutable),这保留了纯粹性,因为状态永远不会改变。要做到这一点,我们必须创建一个对象来冻结它。
const immutableState = Object.freeze({ minimum: 21 });
副作用可能包括……
让我们更深入地了解这些“副作用”,以提高我们的直觉。那么,在纯函数定义中提到的这个无疑是“邪恶”的副作用到底是什么?我们将作用(effect)称为计算过程中除了计算结果之外发生的任何事情。
作用本身并没有什么本质上的坏处,在接下来的章节中,我们将大量使用它们。是副(side)这个词带有负面含义。水本身并不是天然的幼虫孵化器,是停滞的部分导致了蚊虫滋生,我向你保证,副作用在你自己的程序中也是类似的滋生地。
副作用是指在计算结果期间发生的系统状态的改变或与外部世界的可观察的交互(observable interaction)。
副作用可能包括但不限于:
- 改变文件系统
- 向数据库插入记录
- 发起 http 调用
- 数据改变(mutations)
- 打印到屏幕/日志记录
- 获取用户输入
- 查询 DOM
- 访问系统状态
等等等等。任何与函数外部世界的交互都是副作用,这个事实可能会让你怀疑不使用副作用进行编程的实用性。函数式编程的哲学假设副作用是导致行为不正确的主要原因。
这并不是说我们被禁止使用它们,而是我们想要控制它们,并以可控的方式运行它们。我们将在后面章节学习函子(functors)和单子(monads)时学习如何做到这一点,但现在,让我们试着将这些潜藏的非纯函数与我们的纯函数分开。
副作用使函数失去纯函数的资格。这是有道理的:根据定义,纯函数对于相同的输入必须始终返回相同的输出,这在处理我们局部函数之外的事情时是无法保证的。
让我们仔细看看为什么我们坚持对于每个输入都有相同的输出。竖起你的衣领,我们要看一些八年级的数学了。
八年级的数学
来自 mathisfun.com:
函数是值之间的一种特殊关系: 它的每个输入值都只返回一个输出值。
换句话说,它只是两个值之间的关系:输入和输出。虽然每个输入只有一个输出,但该输出不一定对于每个输入都是唯一的。下图显示了一个从 x 到 y 的完全有效的函数图;
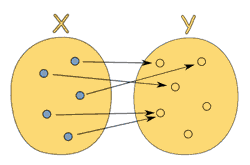 (https://www.mathsisfun.com/sets/function.html)
(https://www.mathsisfun.com/sets/function.html)
相比之下,下图显示了一个不是函数的关系,因为输入值 5 指向了多个输出:
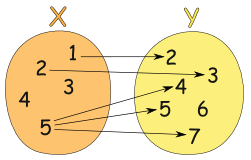 (https://www.mathsisfun.com/sets/function.html)
(https://www.mathsisfun.com/sets/function.html)
函数可以描述为一组位置为(输入,输出)的对:[(1,2), (3,6), (5,10)](看起来这个函数将其输入加倍了)。
或者一个表格:
| 输入 | 输出 |
|---|---|
| 1 | 2 |
| 2 | 4 |
| 3 | 6 |
甚至是一个以 x 为输入、y 为输出的图形:
如果输入决定了输出,就不需要实现细节。由于函数仅仅是输入到输出的映射,人们可以简单地记下对象字面量,并使用 [] 而不是 () 来运行它们。
const toLowerCase = {
A: 'a',
B: 'b',
C: 'c',
D: 'd',
E: 'e',
F: 'f',
};
toLowerCase['C']; // 'c'
const isPrime = {
1: false,
2: true,
3: true,
4: false,
5: true,
6: false,
};
isPrime[3]; // true
当然,你可能想要计算而不是手动写出所有内容,但这说明了思考函数的另一种方式。(你可能在想“那带有多个参数的函数呢?”。确实,在数学角度思考时这带来了一些不便。目前,我们可以将它们捆绑在一个数组中,或者仅仅将 arguments 对象视为输入。当我们学习柯里化(currying)时,我们将看到如何直接模拟函数的数学定义。)
激动人心的揭示来了:纯函数就是数学函数,它们是函数式编程的核心。使用这些小天使进行编程可以带来巨大的好处。让我们看看为什么我们愿意不遗余力地保持纯粹性。
支持纯粹性的理由
可缓存性
首先,纯函数总是可以通过输入进行缓存。这通常使用一种称为记忆化(memoization)的技术来完成:
const squareNumber = memoize(x => x * x);
squareNumber(4); // 16
squareNumber(4); // 16,返回输入 4 的缓存结果
squareNumber(5); // 25
squareNumber(5); // 25,返回输入 5 的缓存结果
这是一个简化的实现,尽管有许多更健壮的版本可用。
const memoize = (f) => {
const cache = {};
return (...args) => {
const argStr = JSON.stringify(args);
// 如果缓存中没有,则计算并存入缓存
cache[argStr] = cache[argStr] || f(...args);
return cache[argStr];
};
};
值得注意的是,你可以通过延迟求值将一些非纯函数转换为纯函数:
const pureHttpCall = memoize((url, params) => () => $.getJSON(url, params));
这里的有趣之处在于我们实际上并没有进行 http 调用——相反,我们返回了一个函数,该函数在被调用时才会执行 http 调用。这个函数是纯粹的,因为它对于相同的输入总是返回相同的输出:即那个给定 url 和 params 后会进行特定 http 调用的函数。
我们的 memoize 函数工作得很好,尽管它不缓存 http 调用的结果,而是缓存生成的函数。
这目前还不是很有用,但我们很快就会学到一些技巧来让它变得有用。关键在于我们可以缓存每个函数,无论它们看起来多么具有破坏性。
可移植性 / 自文档化
纯函数是完全自包含的。函数所需的一切都已准备好并呈现在它面前。思考一下……这可能有什么好处?首先,函数的依赖关系是显式的,因此更容易查看和理解——底层没有任何猫腻。
// 非纯函数
const signUp = (attrs) => {
const user = saveUser(attrs);
welcomeUser(user);
};
// 纯函数
const signUp = (Db, Email, attrs) => () => {
const user = saveUser(Db, attrs);
welcomeUser(Email, user);
};
这里的例子表明,纯函数必须坦诚其依赖关系,因此,它确切地告诉我们它在做什么。仅仅从它的签名,我们就知道它将使用一个 Db、一个 Email 和 attrs,这至少应该能说明一些问题。
我们将学习如何使这样的函数变纯,而不仅仅是延迟求值,但重点应该很清楚,纯粹的形式比其偷偷摸摸的非纯对应物提供了更多信息,后者天知道在做什么。
另一件值得注意的事情是,我们被迫“注入”依赖,或者将它们作为参数传递,这使得我们的应用程序更加灵活,因为我们已经参数化了我们的数据库或邮件客户端或其他任何东西(别担心,我们会看到一种方法使这比听起来更不繁琐)。如果我们选择使用不同的数据库,我们只需要用它来调用我们的函数。如果我们发现自己正在编写一个新应用程序,并且希望重用这个可靠的函数,我们只需将当时可用的任何 Db 和 Email 传递给这个函数。
在 JavaScript 环境中,可移植性可能意味着序列化并通过套接字发送函数。它可能意味着在 web workers 中运行我们所有的应用程序代码。可移植性是一个强大的特性。
与命令式编程中深深植根于其环境(通过状态、依赖关系和可用副作用)的“典型”方法和过程相反,纯函数可以在我们心之所向的任何地方运行。
你上一次将一个方法复制到一个新应用程序是什么时候?我最喜欢的一句引言来自 Erlang 的创造者 Joe Armstrong:“面向对象语言的问题在于它们携带了所有这些隐含的环境。你想要一根香蕉,但你得到的是一只拿着香蕉的大猩猩……以及整个丛林”。
可测试性
接下来,我们意识到纯函数使测试变得容易得多。我们不必模拟一个“真实”的支付网关,也不必在每次测试后设置和断言世界的状态。我们只需给函数输入并断言输出。
事实上,我们发现函数式社区正在开创新的测试工具,这些工具可以用生成的输入“轰炸”我们的函数,并断言输出满足某些属性。这超出了本书的范围,但我强烈建议你搜索并尝试 Quickcheck——一个专为纯函数式环境量身定制的测试工具。
易于推理
许多人认为使用纯函数最大的好处是引用透明性(referential transparency)。如果一段代码可以用它的计算结果值替换,而不会改变程序的行为,那么这段代码就具有引用透明性。
由于纯函数没有副作用,它们只能通过其输出值影响程序的行为。此外,由于它们的输出值可以仅使用其输入值可靠地计算出来,因此纯函数将始终保持引用透明性。让我们看一个例子。
const { Map } = require('immutable');
// 别名:p = player, a = attacker, t = target
const jobe = Map({ name: 'Jobe', hp: 20, team: 'red' });
const michael = Map({ name: 'Michael', hp: 20, team: 'green' });
const decrementHP = p => p.set('hp', p.get('hp') - 1);
const isSameTeam = (p1, p2) => p1.get('team') === p2.get('team');
const punch = (a, t) => (isSameTeam(a, t) ? t : decrementHP(t));
punch(jobe, michael); // Map({name:'Michael', hp:19, team: 'green'})
decrementHP、isSameTeam 和 punch 都是纯函数,因此具有引用透明性。我们可以使用一种称为等式推导(equational reasoning)的技术,即用“等价物替换等价物”来推理代码。这有点像手动评估代码,而不考虑程序化评估的怪癖。利用引用透明性,让我们稍微玩一下这段代码。
首先,我们将内联函数 isSameTeam。
const punch = (a, t) => (a.get('team') === t.get('team') ? t : decrementHP(t));
由于我们的数据是不可变的,我们可以简单地用实际值替换团队名称。
const punch = (a, t) => ('red' === 'green' ? t : decrementHP(t));
我们看到在这种情况下它是 false,所以我们可以移除整个 if 分支。
const punch = (a, t) => decrementHP(t);
如果我们内联 decrementHP,我们会看到,在这种情况下,punch 变成了一个将 hp 减 1 的调用。
const punch = (a, t) => t.set('hp', t.get('hp') - 1);
这种推理代码的能力对于重构和理解代码非常有帮助。事实上,我们使用这种技术重构了我们的海鸥群程序。我们使用等式推导来利用加法和乘法的性质。确实,我们将在整本书中使用这些技术。
并行代码
最后,也是最关键的一点,我们可以并行运行任何纯函数,因为它不需要访问共享内存,并且根据定义,它不会因为某些副作用而产生竞争条件。
这在具有线程的服务端 js 环境以及在浏览器中使用 web workers 是非常可行的,尽管当前的文化似乎因为处理非纯函数时的复杂性而避免使用它。
总结
我们已经了解了什么是纯函数,以及为什么我们作为函数式程序员相信它们是“猫的晚礼服”(即非常棒的东西)。从现在开始,我们将努力以纯粹的方式编写所有函数。我们需要一些额外的工具来帮助我们做到这一点,但与此同时,我们将尝试将非纯函数与其余的纯代码分开。
没有一些额外的工具在手,用纯函数编写程序有点费力。我们必须通过到处传递参数来处理数据,我们被禁止使用状态,更不用说副作用了。人们如何编写这些“自讨苦吃”的程序呢?让我们获取一个名为柯里化(curry)的新工具。