第六章:示例应用程序
声明式编程
我们将要转变我们的思维方式。从现在开始,我们将不再告诉计算机如何完成工作,而是编写一份我们期望得到的结果的规约(specification)。我相信你会发现这比试图一直进行微观管理(micromanage)要轻松得多。
声明式(Declarative),相对于命令式(imperative),意味着我们将编写表达式(expressions),而不是一步步的指令。
想想 SQL。没有“先做这个,再做那个”。只有一个表达式指定了我们想要从数据库中得到什么。我们不决定如何完成工作,而是由它(数据库)决定。当数据库升级并且 SQL 引擎优化时,我们不必更改我们的查询。这是因为有多种方式来解释我们的规约并达到相同的结果。
对于某些人来说,包括我自己,一开始很难掌握声明式编程的概念,所以让我们指出几个例子来体会一下。
// 命令式
const makes = [];
for (let i = 0; i < cars.length; i += 1) {
makes.push(cars[i].make);
}
// 声明式
const makes = cars.map(car => car.make);
命令式的循环必须首先实例化数组。解释器必须先求值这个语句才能继续。然后它直接遍历汽车列表,手动增加一个计数器,并以一种直白的方式展示了显式迭代的细节。
map 版本是一个表达式。它不需要任何特定的求值顺序。这里对于 map 函数如何迭代以及返回的数组如何组装有很大的自由度。它指定了做什么,而不是怎么做。因此,它被打上了声明式的闪亮标签。
除了更清晰、更简洁之外,map 函数可以随意优化,而我们宝贵的应用程序代码无需改变。
对于那些认为“是的,但是命令式循环快得多”的人,我建议你了解一下 JIT(Just-In-Time compiler)如何优化你的代码。这里有一个可能有所启发的精彩视频
这是另一个例子。
// 命令式
const authenticate = (form) => {
const user = toUser(form);
return logIn(user);
};
// 声明式
const authenticate = compose(logIn, toUser);
尽管命令式版本未必有什么错,但仍然内嵌了编码好的、按部就班的求值过程。compose 表达式只是陈述了一个事实:身份验证是 toUser 和 logIn 的组合。同样,这为支持代码的变更留下了回旋余地,并使我们的应用程序代码成为一个高层规约。
在上面的例子中,求值顺序是指定的(toUser 必须在 logIn 之前调用),但在许多场景中,顺序并不重要,这可以通过声明式编程轻松指定(稍后会详细介绍)。
因为我们不必编码求值顺序,声明式编程有助于并行计算。这一点再加上纯函数,就是为什么函数式编程(FP)是并行未来的一个好选择——我们实际上不需要做任何特别的事情来实现并行/并发系统。
函数式编程的 Flickr 应用一瞥
我们现在将以声明式的、可组合的方式构建一个示例应用程序。我们暂时仍然会作弊并使用副作用(side effects),但我们会将它们保持在最小程度并与我们的纯代码库分开。我们将构建一个浏览器部件(widget),用于从 Flickr 获取图片并显示它们。让我们从搭建应用程序的骨架开始。这是 HTML:
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Flickr App</title>
</head>
<body>
<main id="js-main" class="main"></main>
<script src="https://cdnjs.cloudflare.com/ajax/libs/require.js/2.2.0/require.min.js"></script>
<script src="main.js"></script>
</body>
</html>
这是 main.js 的骨架:
const CDN = s => `https://cdnjs.cloudflare.com/ajax/libs/${s}`;
const ramda = CDN('ramda/0.21.0/ramda.min');
const jquery = CDN('jquery/3.0.0-rc1/jquery.min');
requirejs.config({ paths: { ramda, jquery } });
requirejs(['jquery', 'ramda'], ($, { compose, curry, map, prop }) => {
// 应用程序代码放在这里
});
我们引入了 ramda 而不是 lodash 或其他工具库。它包含了 compose、curry 等更多函数。我使用了 requirejs,这可能看起来有点小题大做,但我们将在整本书中使用它,保持一致性是关键。
好了,准备工作就绪,接下来是规约。我们的应用程序将做 4 件事:
- 为我们的特定搜索词构建一个 URL
- 进行 Flickr API 调用
- 将返回的 JSON 转换为 HTML 图片
- 将它们放置到屏幕上
上面提到了 2 个非纯(impure)操作。你看到它们了吗?就是那些关于从 Flickr API 获取数据和将数据放置到屏幕上的部分。让我们首先定义它们,以便我们可以隔离它们。另外,我将添加我们好用的 trace 函数以便于调试。
const Impure = {
getJSON: curry((callback, url) => $.getJSON(url, callback)), // 包装 $.getJSON
setHtml: curry((sel, html) => $(sel).html(html)), // 包装 $().html
trace: curry((tag, x) => { console.log(tag, x); return x; }), // 用于调试的追踪函数
};
这里我们简单地包装了 jQuery 的方法,使它们柯里化(curried),并且我们将参数交换到更有利的位置。我用 Impure 为它们添加了命名空间,这样我们就知道这些是危险的函数。在未来的例子中,我们将使这两个函数变纯。
接下来我们必须构建一个 URL 传递给我们的 Impure.getJSON 函数。
const host = 'api.flickr.com';
const path = '/services/feeds/photos_public.gne';
const query = t => `?tags=${t}&format=json&jsoncallback=?`; // 构建查询字符串
const url = t => `https://${host}${path}${query(t)}`; // 完整的 URL
有一些花哨且过于复杂的方式可以用幺半群(monoids,我们稍后会学习)或组合子(combinators)来编写 pointfree 风格的 url 函数。我们选择坚持使用可读的版本,并以普通的有参数(pointful)方式组装这个字符串。
让我们编写一个应用程序函数,它进行调用并将内容放置到屏幕上。
const app = compose(Impure.getJSON(Impure.trace('response')), url); // 先生成 url,然后调用 getJSON(回调是 trace)
app('cats'); // 使用 'cats' 作为搜索词启动应用
这将调用我们的 url 函数,然后将该字符串传递给我们的 getJSON 函数,该函数已用 trace 进行了部分应用(partially applied)。加载应用程序将在控制台中显示 API 调用的响应。
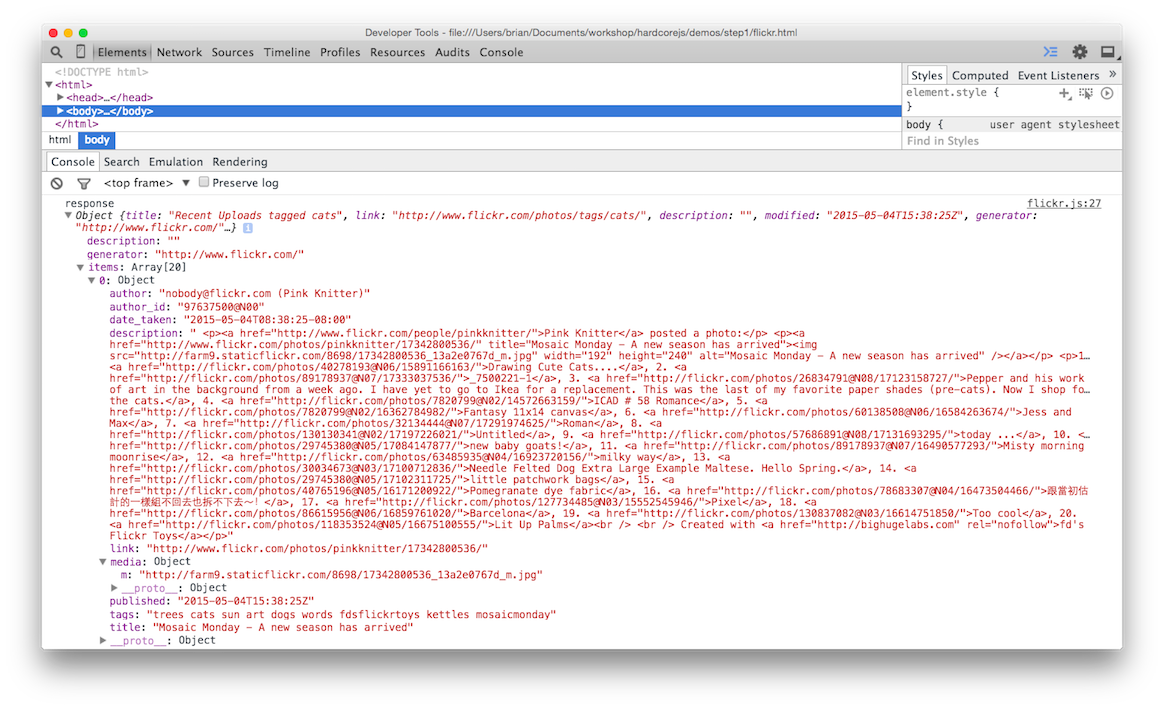
我们想用这个 JSON 来构建图片。看起来 mediaUrls 藏在 items 里面,然后是每个 media 的 m 属性。
无论如何,要获取这些嵌套属性,我们可以使用 ramda 中一个好用的通用获取函数,叫做 prop。这是一个自制版本,这样你就能明白发生了什么:
const prop = curry((property, object) => object[property]); // 获取对象属性的柯里化函数
它其实相当乏味。我们只是使用 [] 语法来访问任何对象上的属性。让我们用它来获取我们的 mediaUrls。
const mediaUrl = compose(prop('m'), prop('media')); // 获取 media.m
const mediaUrls = compose(map(mediaUrl), prop('items')); // 获取 items,然后 map(mediaUrl)
一旦我们收集了 items,我们必须对其进行 map 操作来提取每个媒体 URL。这会得到一个整洁的 mediaUrls 数组。让我们把它接入我们的应用程序并在屏幕上打印它们。
const render = compose(Impure.setHtml('#js-main'), mediaUrls); // 获取 mediaUrls,然后设置 HTML
const app = compose(Impure.getJSON(render), url); // 生成 url,然后调用 getJSON(回调是 render)
我们所做的只是创建了一个新的组合,它将调用我们的 mediaUrls 并用它们设置 <main> 的 HTML。既然我们有东西可以渲染(而不是原始 JSON),我们就用 render 替换了 trace 调用。这将粗略地在 body 中显示我们的 mediaUrls。
我们最后一步是将这些 mediaUrls 转换成真正的 images(图片)。在一个更大的应用程序中,我们会使用像 Handlebars 或 React 这样的模板/DOM 库。但对于这个应用程序,我们只需要一个 img 标签,所以让我们继续使用 jQuery。
const img = src => $('<img />', { src }); // 创建一个 img 元素的函数
jQuery 的 html 方法接受一个标签数组。我们只需要将我们的 mediaUrls 转换成图片,并将它们传递给 setHtml。
const images = compose(map(img), mediaUrls); // 获取 mediaUrls,然后 map(img) 转换成图片标签
const render = compose(Impure.setHtml('#js-main'), images); // 获取 images 数组,然后设置 HTML
const app = compose(Impure.getJSON(render), url); // 最终的应用组合
我们就完成了!
这是完成后的脚本:
const CDN = s => `https://cdnjs.cloudflare.com/ajax/libs/${s}`;
const ramda = CDN('ramda/0.21.0/ramda.min');
const jquery = CDN('jquery/3.0.0-rc1/jquery.min');
requirejs.config({ paths: { ramda, jquery } });
require(['jquery', 'ramda'], ($, { compose, curry, map, prop }) => {
// -- Utils ----------------------------------------------------------
const Impure = {
trace: curry((tag, x) => { console.log(tag, x); return x; }), // eslint-disable-line no-console
getJSON: curry((callback, url) => $.getJSON(url, callback)),
setHtml: curry((sel, html) => $(sel).html(html)),
};
// -- Pure -----------------------------------------------------------
const host = 'api.flickr.com';
const path = '/services/feeds/photos_public.gne';
const query = t => `?tags=${t}&format=json&jsoncallback=?`;
const url = t => `https://${host}${path}${query(t)}`;
const img = src => $('<img />', { src });
const mediaUrl = compose(prop('m'), prop('media'));
const mediaUrls = compose(map(mediaUrl), prop('items'));
const images = compose(map(img), mediaUrls);
// -- Impure ---------------------------------------------------------
const render = compose(Impure.setHtml('#js-main'), images);
const app = compose(Impure.getJSON(render), url);
app('cats');
});
现在看看这个。一个漂亮的声明式规约,描述事物是什么,而不是它们如何产生。我们现在将每一行视为一个具有成立属性的等式。我们可以使用这些属性来推理我们的应用程序并进行重构(refactor)。
有原则的重构
有一个可用的优化(optimization)——我们对每个 item 进行 map 操作将其转换为媒体 URL,然后我们再次对这些 mediaUrls 进行 map 操作将其转换为 img 标签。关于 map 和组合有一条定律:
// map 的组合律
compose(map(f), map(g)) === map(compose(f, g));
我们可以使用这个属性来优化我们的代码。让我们进行一次有原则的重构。
// 原始代码
const mediaUrl = compose(prop('m'), prop('media'));
const mediaUrls = compose(map(mediaUrl), prop('items'));
const images = compose(map(img), mediaUrls);
让我们对齐我们的 map 操作。得益于等式推导(equational reasoning)和纯粹性(purity),我们可以在 images 中内联对 mediaUrls 的调用。
const mediaUrl = compose(prop('m'), prop('media'));
const images = compose(map(img), map(mediaUrl), prop('items')); // 内联 mediaUrls
现在我们已经对齐了我们的 map,我们可以应用组合律了。
/*
compose(map(f), map(g)) === map(compose(f, g));
// 应用定律:f = img, g = mediaUrl
compose(map(img), map(mediaUrl)) === map(compose(img, mediaUrl));
*/
const mediaUrl = compose(prop('m'), prop('media'));
const images = compose(map(compose(img, mediaUrl)), prop('items')); // 应用 map 组合律
现在代码只会循环一次,同时将每个 item 转换为 img。让我们通过提取函数让它更具可读性。
const mediaUrl = compose(prop('m'), prop('media'));
const mediaToImg = compose(img, mediaUrl); // 将 mediaUrl 转换为 img 的组合
const images = compose(map(mediaToImg), prop('items')); // 提取组合后的函数
总结
我们已经看到了如何在一个小型但真实的应用程序中将我们的新技能付诸实践。我们使用了我们的数学框架来推理和重构我们的代码。但是错误处理和代码分支呢?我们如何使整个应用程序纯粹,而不仅仅是将破坏性函数放入命名空间?我们如何使我们的应用程序更安全、更具表现力?这些是我们将在第二部分中解决的问题。